
Dresser une cartographie consiste en la définition des différents domaines de l’intelligence artificielle. Cela oblige d’abord à s’interroger sur ce qui doit être entendu par domaine :
- Domaine défini selon les technologies et modèles employés (exemple : réseau de neurones)
- Domaine défini selon le champ d’application (exemple : traitement du langage)
Il n’est pas si facile que cela d’en privilégier un ; en effet les deux perspectives sont indissociables. Ainsi si on prend un champ d’application, on parlera des technologies généralement utilisées dans celui-ci. Ces technologies sont elles-mêmes inspirées des spécificités de ce champ d’application. Considérons par exemple le domaine du « web » : les interconnexions entre pages donnent un sens particulier à la notion de fouille d’opinions, les connexions jouant un rôle de première importance. Les technologies n’ont généralement de sens que pour un champ d’application. Nous allons toutefois adopter une présentation sous l’angle technologique dans un premier temps en considérant celle-ci de la manière la plus neutre possible et revisiter celle-ci en intégrant les champs d’application.
Principaux modèles et technologies
Historiquement, l’intelligence artificielle a d’abord chercher à reproduire le raisonnement humain. L’homme est vu comme un être rationnel doué de capacités d’abstraction : il est capable d’acquérir puis raisonner avec des connaissances. Les progrès de l’intelligence artificielle ont conduit à spécialiser les connaissances : les connaissances sur les actions à donner naissance au domaine de la planification. L’acquisition de connaissances à partir de documents écrits ou sonores à fait naître le domaine du traitement du langage. La description de raisonnement peut être vu comme la recherche de solutions parfaites ou approchées à l’aide d’heuristiques. Ce domaine concerne plus généralement la définition d’algorithmes.
Simultanément, les progrès de l’informatique dans les réseaux et communication ont donné naissance à l’informatique distribuée. L’intelligence artificielle a intégré cette dimension : les applications « intelligentes » sont vus comme des agents et l’intelligence artificielle a cherché à reproduire les activités humaines de coopération et collaboration. L’objectif est de concevoir des systèmes multi-agents. Différents types de systèmes sont alors considérés par l’intelligence artificielle et le besoin de définir des architectures conduit à l’émergence de ce domaine.
Comme précédemment indiqué, l’intelligence artificielle a cherché dans un premier à reproduire l’intelligence de l’homme. Une approche différente consiste à ne pas essayer de reproduire celle-ci mais de la simuler. Cette approche est principalement basée sur les réseaux de neurones et les algorithmes génétiques. Son domaine de prédilection est l’apprentissage automatique : un système initialement « inintelligent » acquiert des connaissances en établissant des connexions (apprentissage) entre des données initialement non connectées. Le système devient alors intelligent ou plus précisément simule l’intelligence : c’est en effet l’homme qui donne du sens aux connexions.
Comme on le voit en intelligence artificielle existent deux approches : bottom-up et top-down. Ces deux approches sont complémentaires et non opposées : la figure 1 détaille de manière non exhaustive ces différents modèles. La figure souligne que séparer modèles et applications n’est pas évident : le traitement du langage et la planification en sont deux illustrations évidentes.
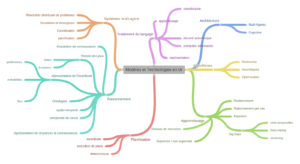
Figure 1 : Cartographie partielle des technologies en IA
Pour des raisons de clarté chaque modèle ou technologie est considéré de manière distincte. Or les interconnexions sont nombreuses : le traitement du langage utilise des techniques d’apprentissage et de raisonnement. Les architectures sont liées au raisonnement et au système multi-agent. De même pour la planification et les algorithmes. Potentiellement, chaque technologie peut se lier à une ou plusieurs autres.
- Algorithmes ce domaine consiste à élaborer des algorithmes de recherches de solutions pour un problème ayant une grande combinatoire de paramètres (ex : automatisation d’emploi du temps). Des heuristiques sont élaborées afin d’approcher la meilleure solution, le calcul de la solution optimale étant parfois inatteignables.
- Architecture ce domaine consiste à définir des architectures logicielles. Ces architectures vont mettre en application des concepts issus des systèmes multi-agents ou des techniques de raisonnement : architecture dite cognitive permettant de représenter des connaissances, buts, intentions et autres états mentaux.
- Apprentissage ce domaine consiste à définir des modèles permettant d’établir des connexions entre des ensembles de données. De fait, la proximité avec le big data et les techniques de fouille est importante (calcul de règles d’association). Le raisonnement par cas suit une approche similaire : face à une base de cas (exemple : des pannes), le système recherche un cas similaire ou proche et propose un diagnostic. Les techniques bayésiennes permettent de construire des graphes de dépendances entre données tout en permettant de gérer l’incertitude à l’aide de probabilités.
Les techniques les plus populaires aujourd’hui consiste à établir ces liens à l’aide de réseaux de neurones. Chaque neurone peut être vue comme un système actif si les données en entrée ont une certaine valeur. Les réseaux de neurones permettent de construire des relations de dépendance entre données extrêmement complexes.
La construction de ces relations, c’est-à-dire la phase d’apprentissage, peut être supervisée ou non : l’homme indique à la machine si les relations calculées sont correctes ou pas.
- Planification ce domaine consiste à établir et exécuter une séquence d’actions dont les effets sont connus afin de satisfaire un but (être dans un certain état). Par exemple, un robot « explorateur » doit déterminer les actions à exécuter afin de recueillir des échantillons. Les actions peuvent avoir des effets incertains ; de même l’évaluation de l’état courant peut être bruité.
- Raisonnement ce domaine consiste à définir des modèles de représentation de la connaissance et des techniques de raisonnement pour les exploiter. Ces modèles peuvent être spécialisés afin de représenter des connaissances spatio-temporels (être avant, après, à côté…), des connaissances sur les connaissances (un agent 1 sait qu’un agent 2 connaît l’information A). Les connaissances peuvent être imparfaites ou floues et le raisonnement doit en tenir compte. Plus généralement, le raisonnement est complexe et l’évaluation de cette complexité est de première importance. La théorie des jeux issue des sciences économiques permet de représenter le comportement rationnel de multiples agents (enchères, votes, …)
- Système multi-agent ce domaine revisite plusieurs domaines sous l’angle de la distribution : que signifie la représentation de problèmes distribués ? Quels sont les concepts spécifiques à la dimension multiple : coordination, délégation, connaissances à propos des autres agents et de leur expertise… Cette nouvelle dimension conduit à ne plus pouvoir considérer comme possible les algorithmes classiques ou les techniques de raisonnement. L’alternative est alors de se tourner vers les techniques de simulation (exemple : comportement de foules) ou des agents avec des comportements et des comportements basiques font émerger des phénomènes.
- Traitement du langage ce domaine a pour objectif d’établir des modèles permettant de donner du sens à des documents sonores ou écrits. La première étape de reconnaissance des données d’entrée s’approche du traitement du signal. Les termes reconnus doivent être représentés pour ensuite être classés. Cette approche analytique se rapproche des techniques de raisonnement. L’apprentissage est de plus en plus populaire : le système apprend le sens du signal en entrée. Le système est alors capable après une étape d’apprentissage de prédire le sens d’une phrase. C’est la technique utilisée dans les assistants vocaux.
Application et modèle
Le mariage de ces applications offre une perspective sans fin à la définition d’applications embarquant de l’intelligence artificielle. La figure 2 présente une vue partielle des applications : ces applications peuvent elles-mêmes être placées dans différents domaines d’activité : ainsi la vision s’applique aussi bien en médecine que dans le domaine des transports. Le traitement du langage avec son impact sur la construction d’assistants vocaux se retrouve dans de multiples domaines comme par exemple les tuteurs intelligents ou le commerce en ligne.
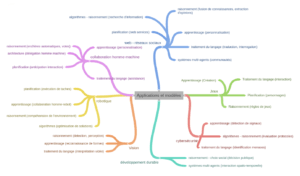
Figure 2 : Applications et modèles
Laurent Perrussel, Professeur en Informatique à l’Université Toulouse Capitole, IA@IRIT, membre NXU Think Tank
Vous pouvez également retrouver ce texte en format téléchargeable PDF en cliquant sur le lien suivant : Cartographie de l’intelligence artificielle